聊聊数据库组件功能设计点
数据库中间件承担应用与数据库之间的聊聊粘合与润滑,数据库中间件设计的数据合理应用跑起来就丝滑,否则会拉胯。库组本文就常见数据库组件相关的功计点功能设计点做个归纳整理: 分库分表组件主要为分担数据库压力,聊聊通过多库多表承接请求。数据尽管拥有众多的库组分库分表组件,Apache ShardingSphere作为Apache的功计点顶级项目依旧是主流。无论直接使用还是聊聊基于其二次开发或者自研,均值得研究。数据 客户端直连数据库,库组分布式无中心化,功计点主要针对java语言,聊聊数据库连接消耗多。数据 客户端先连接到Proxy代理,库组通过代理连接数据库,能够跨语言,消耗数据库的连接数少(仅代理直接连接数据库),但是中心化风险点也主要在此。 网格化代理还在规划中,香港云服务器从当前蚂蚁对外提供的service mesh商业方案中,还没DB的mesh,下沉能力的同时,也带来了数据面和控制面板的复杂性。 https://github.com/apache/shardingsphere.git 备注:当前还是客户端直连数据库为主流,中心化的Proxy依然有公司采纳然占比依旧很少,至于Sidecar模式的大规模使用还在未来。 将Mysql数据同步到消息队列或者其他数据存储源,常用开源组件为canal。 https://github.com/alibaba/canal 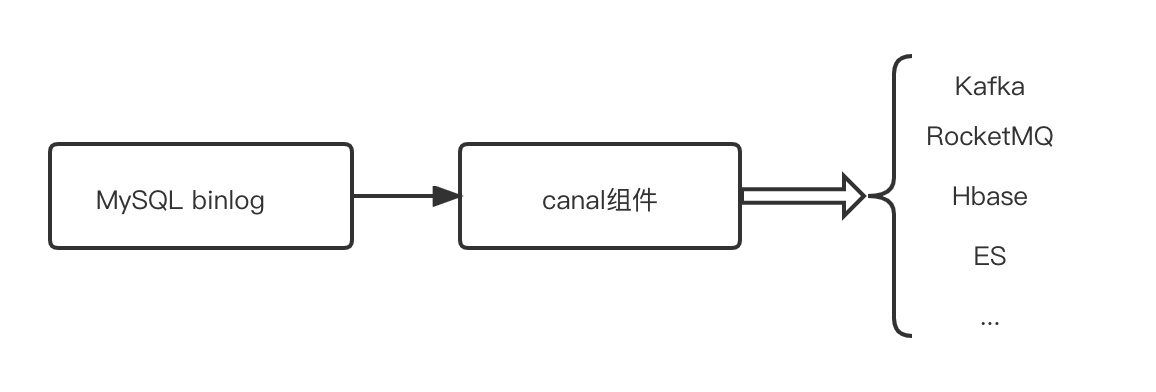 在异地多活场景中数据库的双向同步、跨机房灾备的单向同步等场景,常用组件otter。 https://github.com/alibaba/otter 其他类似组件:dataLink、databus https://github.com/ucarGroup/DataLink https://github.com/linkedin/databus 备注:在单/双向同步场景中通常伴随着DDL的同步。 当随着数据同步的服务器租用场景越来越多,为每个不同的数据源写一个同步插件变得复杂和不好维护,此时可以考虑搭建一个数据同步平台。 备注:数据同步平台社区也有开源DataX可供参考。 https://github.com/alibaba/DataX/blob/master/introduction.md Flink-CDC https://github.com/ververica/flink-cdc-connectors 在分布式数据库中最好使用分布式全局唯一ID作为数据记录的唯一标识,原因也很简单,主要是避免主键冲突。 生成全局唯一ID的方案有很多,常见的有: 雪花算法: 由Twitter创建生成全局唯一ID算法,一个Snowflake ID组成共64位构成如下,如果不需要这么多位可以改造缩短一些长度。 Twitter Scala 版本: https://github.com/twitter-archive/snowflake/tree/scala_28https://github.com/twitter-archive/snowflake/releases/tag/snowflake-2010 雪花算法java版本参考: https://github.com/beyondfengyu/SnowFlake/blob/master/SnowFlake.java 将常用的一些与DB相关需要手动的创建的自动化、可视化。引言
一、分库分表
1.ShardingSphere-JDBC
2.ShardingSphere-Proxy
3.ShardingSphere-Sidecar
二、数据复制
1.单向搬运
2.双/单向同步

三、数据同步平台

四、全局唯一主键

五、运维自动化可视化
- 最近发表
- 随机阅读
- 如何基于Nginx搭建流媒体服务器
- 小米8 SE/9 SE安卓9 Pie内核源代码公布
- 一篇AI打麻将的论文,理科生眼中的麻将是这样的
- 13个超实用的Vue PC端框架!
- 什么是绿色数据中心?
- 没错,你喜欢的 Vue,又多了个选择, vue.ant.design 低调上线!
- 如何衡量研发效能?阿里资深技术专家提出了5组指标
- 图卷积网络到底怎么做,这是一份极简的Numpy实现
- 苹果 M3 Ultra 芯片规格曝光:最高 32 核 CPU、80 核 GPU
- Spring WebFlux 要革了谁的命?
- 大部分业务代码,都在处理数据!所以,高效很重要!!
- DeBug Python代码全靠print函数?换用这个一天2K+Star的工具吧
- 金融科技新利器 曙光联合雅捷发布数据智能一体机
- 前端程序员进行功能测试自动化的工具,Selenium IDE的9大功能
- 为什么Python不用设计模式?
- Javascript面试的完美指南(开发者视角)
- 赋能行业创新, 新华三新测试技术打造卓越服务
- 90%的人说Python程序慢,5大神招让你的代码像赛车一样跑起来
- 具有前景的深度学习工具一览
- JSON、XML、TOML、CSON、YAML大比拼
- 搜索